概述: 從微服務角度調整系統架構
- 延續上一篇的需求,嘗試以微服務的理念調整架構。
- 最主要的變動是將AWS Lambda Function從Spring Boot改成較為輕量級的Node.js,並使用 Message Queue 將系統拆分為 Producer 和 Consumer 兩個角色,讓兩邊的程式邏輯簡單化,減少相依性,提高維護性和可擴充性。
架構調整需求: 維護性及可擴充性
雖然系統規模不大,我還是希望它能具備像商業系統一樣的運作標準。相關的理論相當多,但我認為直接能做到的,就是依照微服務的主要精神,盡量把系統拆成幾個小範圍、無狀態,且能獨自運作的服務,這樣的設計能方便的抽換服務和水平擴展。
延遲問題
此系統包含一些需要考慮輸入輸出(IO) 及 API 延遲的任務,例如呼叫 Open AI API以及資料庫 IO的延遲等。這些任務的延遲時間較不穩定,不適合擺在AWS Lambda 上執行,因為 Lambda Function 有執行時間的限制(雖然可以調整)。例如早期的Open AI API在prompt字數較多時,偶爾會有多達5秒的延遲,會造成額外的執行成本。
- 根據AWS Lambda目前的定價標準,若Function執行時間和程式量導致儲存個體超過512MB時,就會開始計費:【 Lambda 定價頁面】
解耦合
另外,將事件接收/處理,及其他Bot Server的核心邏輯綁在一起,程式結構會比較複雜,當出現錯誤需要Debug時,比較不容易分清楚是哪一段程式出了問題。
後續要修改相關功能時,也可能會因為過多的相依性造成額外的維護難度。
實作: 具體的技術選擇與架構調整
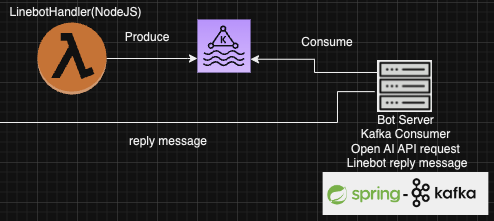
為了因應上述需求,我做了以下調整:
Producer and Consumer 模式: 將事件處理與Bot Server解耦
Producer: 事件處理
- 這部分在AWS Lambda上執行,專注於從Webhook事件中提取使用者輸入的訊息內容、Token,及其他Client端資訊。
- 如果提取成功,會將相關資訊送到Message Queue,任務就算完成; 若資料有誤或提取失敗,則直接返回,不觸發後續邏輯。
- 可擴充性: 由於是在Lambda上執行,可以依照使用需求調整並行配額,預設為1000個
Consumer: Bot Server
- 這部分在AWS EC2上執行,專注於語意判斷及後續邏輯處理。
- 一旦Message Queue有任務,就會取得使用者訊息及Token,經過處理後,使用LINE的API帶上Token回傳結果給使用者。
- Producer 和 Consumer 相互獨立,並不直接呼叫Consumer這邊的Function,所以沒有相依性的問題。
- 可擴充性: Bot Server不具備狀態,只要能讀取的到Kafka中的資料,就能繼續運行,若有需要可隨時依需求升級 / 擴充EC2,執行多個Bot Server。
Message Queue
- 使用Kafka作為訊息佇列,負責Producer 和 Consumer 之間的溝通。
AWS Lambda 事件處理:從 Spring Boot 換成 Node.js
原本使用的Spring Boot必須將程式與依賴包打包成 Uber Jar,才能在 Lambda 上執行。由於這種執行檔無論在執行時間和大小都比較大,不適合做成Lambda Function。故換成檔案較小,更輕量的Node.js作為事件處理的程式語言。
OpenAI的語意辨識從Lambda移至到Bot Server
由於此專案是用Call API的方式實現OpenAI的語意辨識,故會有延遲時間的不確定性,導致在 Lambda 上的執行時間過長。因此,我將語意辨識的功能從 Lambda 移到 Bot Server 上執行。
資料庫選擇:使用 NoSQL (MongoDB)
由於目前的專案需求較為單純,沒有什麼constraint需要限制,也沒有太多資料表同做更動需要的Transaction,故RDBMS提供的原子性(Atomicity) 和 一致性(Consistency)暫時用不到,易用性和水平擴展的靈活性才是更重要的,故資料庫使用MongoDB。

